Automatische Texterkennung (OCR) für arabische Texte habe ich zuletzt im April 2018 ausgiebig getestet. Mein Fazit damals: „OCR und Arabisch vertragen sich nicht“. Zweieinhalb Jahre später ist es höchste Zeit für einen neuen Versuch. Welche Verbesserungen gibt es? Welche Anbieter sind empfehlenswert? Unter welchen Bedingungen kann OCR für arabische Texte funktionieren? Ein Update.
Was macht OCR für Arabisch so schwierig?
An den erschwerten Ausgangsbedingungen hat sich wenig geändert: Eine gute OCR-Software muss bei arabischen Texten deutlich mehr leisten als bei lateinischer Schrift. Ein Überblick über die wichtigsten Herausforderungen:
- Viele arabische Buchstaben sehen sich sehr ähnlich und unterscheiden sich beispielsweise nur darin, ob ein Punkt oberhalb oder unterhalb des Buchstabens gesetzt wird. Das macht es für eine OCR-Software ungleich schwieriger als bei lateinischen Buchstaben, wo der optische Kontrast zwischen den einzelnen Lettern deutlich größer ist. Schon eine kleine Verunreinigung oder ein unscharfer Scan kann einen Buchstaben und damit die Bedeutung des Wortes komplett verändern.
- Arabische Buchstaben können je nach Position im Wort oder in Einzelstellung bis zu 5 verschiedene Erscheinungsformen haben und sehen zusätzlich in Ligaturen noch einmal anders aus. Das erhöht die Komplexität weiter.
- Die meisten arabischen Buchstaben werden durch eine waagerechte Linie miteinander verbunden. Diese Linie kann unterschiedlich lang sein. Die automatische Texterkennung muss aber exakt definieren können, wo ein Buchstabe aufhört und der nächste anfängt. Je nach verwendetem Schrifttyp unterscheiden sich zudem Form und Position einzelner Buchstaben.
- Die Konsonantenschrift macht bei arabischem Text stets unterschiedliche Leseweisen und damit Bedeutungsvarianten von Wörtern und Sätzen möglich. Ein Leser (und damit auch eine Texterkennungssoftware) muss zur korrekten Erkennung die hocharabische Grammatik beherrschen.
- Grammatikalische und lexikalische Eigenheiten des Arabischen kommen hinzu: Präpositionen, Partikel, Personal- und Possessiv-Suffixe werden oft mit dem Bezugswort zusammengeschrieben. Das muss von der OCR-Software ebenfalls erkannt und richtig zugeordnet werden. Viele Texterkennungsprogramme arbeiten zudem mit internen Lexika, um die erkannten Wörter der Sprache korrekt zuordnen zu können und als Rückkoppelung den Text besser zu erkennen. Arabische Wörter weisen allerdings eine enorme Polysemie auf. Das bedeutet: Ein Wort kann je nach Kontext sehr viele verschiedene Bedeutungen haben.
OCR-Software für Arabisch im Test
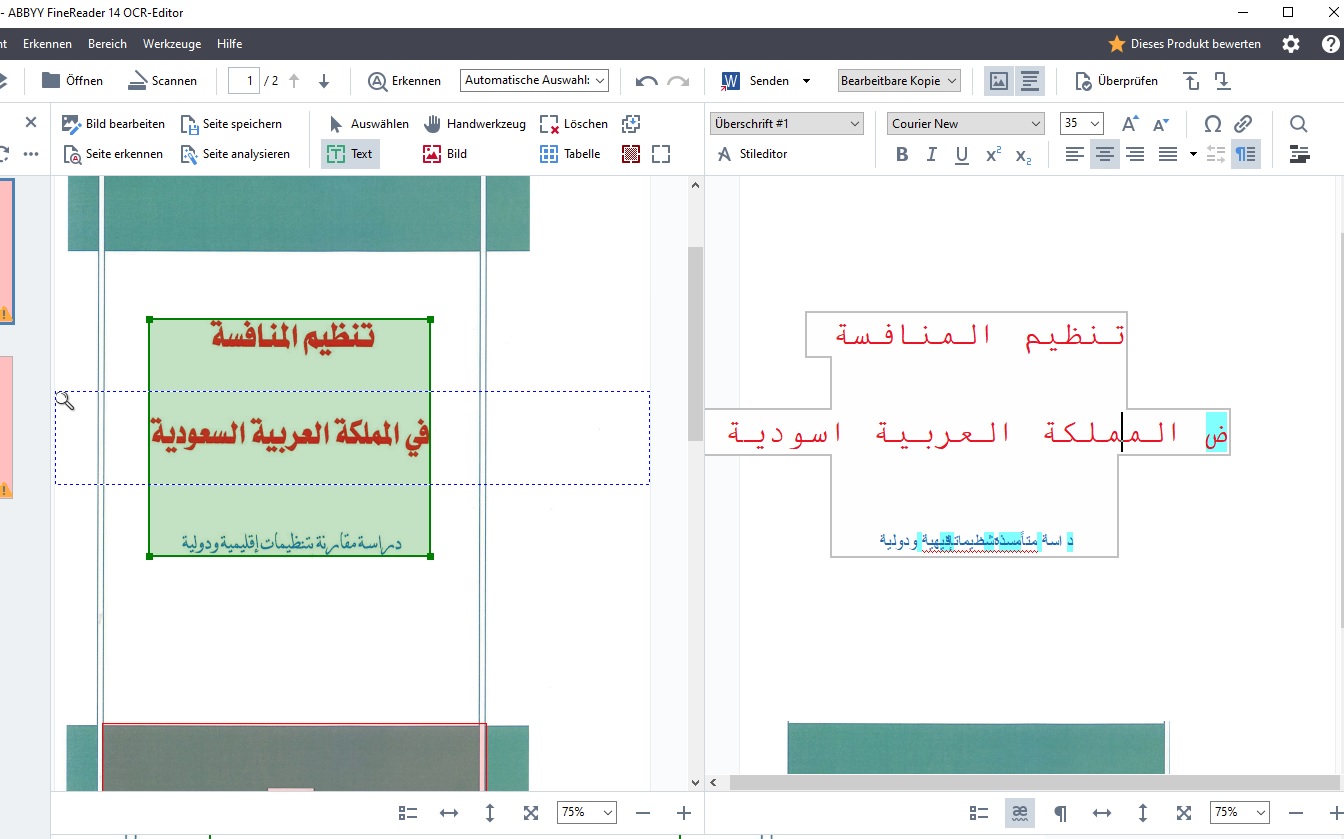
Im Vergleich zu 2018 unterstützen inzwischen deutlich mehr OCR-Anbieter die autmatische Erkennung arabischer Texte. Ich habe drei verschiedene Textsorten mit unterschiedlicher Schrift und Bildqualität durch mehrere OCR Programme erkennen lassen. Darunter waren neben dem ABBY Fine Reader mehrere Online-Anbieter. Insgesamt lieferte der ABBY Fine Reader nach wie vor die besten Ergebnisse. Unter bestimmten Voraussetzungen war der erkannte Text sogar gut brauchbar, wenn auch nicht ganz frei von Fehlern.
Das beste Ergebnis erzielte ich mit dem ausgedruckten Artikel einer Online-Zeitung. Der Ausdruck auf einem weißen Blatt Papier war ohne Verunreinigungen und mit hoher Druckqualität erfolgt, der Text in normalem Schriftschnitt einer Standardschriftart gehalten. Nach erfolgter Texterkennung musste ich lediglich einige verwechselte Buchstaben, Eigennamen und Zahlenangaben korrigieren. Damit lässt sich unter bestimmten Voraussetzungen arbeiten. Leider erfüllen im Alltag die wenigsten Texte diese Voraussetzungen.
Als nächstes kamen zwei Seiten aus einer saudi-arabischen Broschüre über Ausschreibungsbedingungen zum Einsatz. Der Ausdruck erfolgte auch hier in hoher Qualität. Allerdings war der Text in einer untypischen Schriftart geschrieben und enthielt viel fettgedruckten Text. Das Ergebnis war erstaunlich schlecht: Viele Buchstaben wurden verwechselt, Leerzeichen an der falschen Stelle gesetzt und die Fehlerzahl insgesamt so hoch, dass eine Nachbearbeitung nicht zumutbar ist.
Zu guter Letzt ließ ich die Programme auf eine arabische Urkunde los, wie ich sie regelmäßig für beglaubigte Übersetzungen vorliegen habe. Diese Urkunde enthielt wenige Wörter und zusätzlich handschriftliche Einträge. Das Papier war leicht vergilbt, der Text teilweise fett markiert, teilweise mit normalem Schriftschnitt und die Scanauflösung leicht unscharf. Hier versagte die OCR vollständig: Buchstaben wurden verwechselt, Handschrift nicht als solche erkannt und das Layout komplett durcheinandergeworfen. Kurz: Praxistest nicht bestanden.
Fazit: Gute Ergebnisse nur unter „Laborbedingungen“
Mein Fazit zum Testdurchlauf 2020: Die automatische Erkennung arabischer Texte funktioniert inzwischen deutlich besser als noch vor zwei Jahren. Insbesondere Texte in Standardschriftart und guter Druckqualität werden gut erkannt und können mit wenig Aufwand in ein editierbares Format konvertiert werden. Allerdings entsprechen diese Voraussetzungen „Laborbedingungen“, die in – zumindest meiner – Alltagspraxis kaum vorkommen. Die genannten Herausforderungen für OCR mit arabischen Texten bleiben bestehen. Insbesondere müssen die Programme noch besser darin werden, unterschiedliche Schriftarten und Schriftschnitte zu erkennen und die feinen Unterschiede zwischen sehr ähnlichen Buchstaben besser zu identifizieren.
Sie haben noch Fragen zu OCR und Arabisch? Sie möchten einen arabischen Text digitalisieren und benötigen eine Machbarkeitseinschätzung? Kontaktieren Sie mich unter mail@falk-translations.com!
Bildquelle: Dr. Daniel Falk